Ask the Expert: Tips and best practices for AWS S3 security
By Matt Webber

Amazon S3 (Simple Storage Service) is a great utility for any application that requires storage over the Internet.
It gives any developer access to the same data storage infrastructure that Amazon itself uses to run all of its own websites.
For that reason alone, by using it, you know you’re going to get a highly scalable, reliable, and secure solution. Talk about drinking your own champagne.
Now while S3 includes the term simple in its name, there are still certain things you’re required to do to get the best experience out of it.
Arguably the most important of which is to ensure you are following the recommended practices when it comes to data security.
You only need to Google the keywords ‘S3 data breach’ to see the countless examples of where an S3 data breach has occurred.
Previous breaches include the personal data of 198 million American voters being exposed because Deep Root Analytics stored the information on a publicly accessible S3 bucket.
Or when Verizon had a contractor fail to correctly secure a bucket containing account information for 6 million customers, leading to another breach.
Any data breach not only damages the reputation of the offending company but can also cost them dearly in fines and lost business.
Does any of this mean S3 is insecure? Absolutely not. S3 itself is secure— issues tend to appear either when it’s misconfigured or when credentials are compromised.
To help customers understand what they are responsible for, AWS operates under the Shared Responsibility Model.
This means that the responsibility for the security of the cloud is taken care of by AWS, while cloud customers are responsible for security in the cloud.
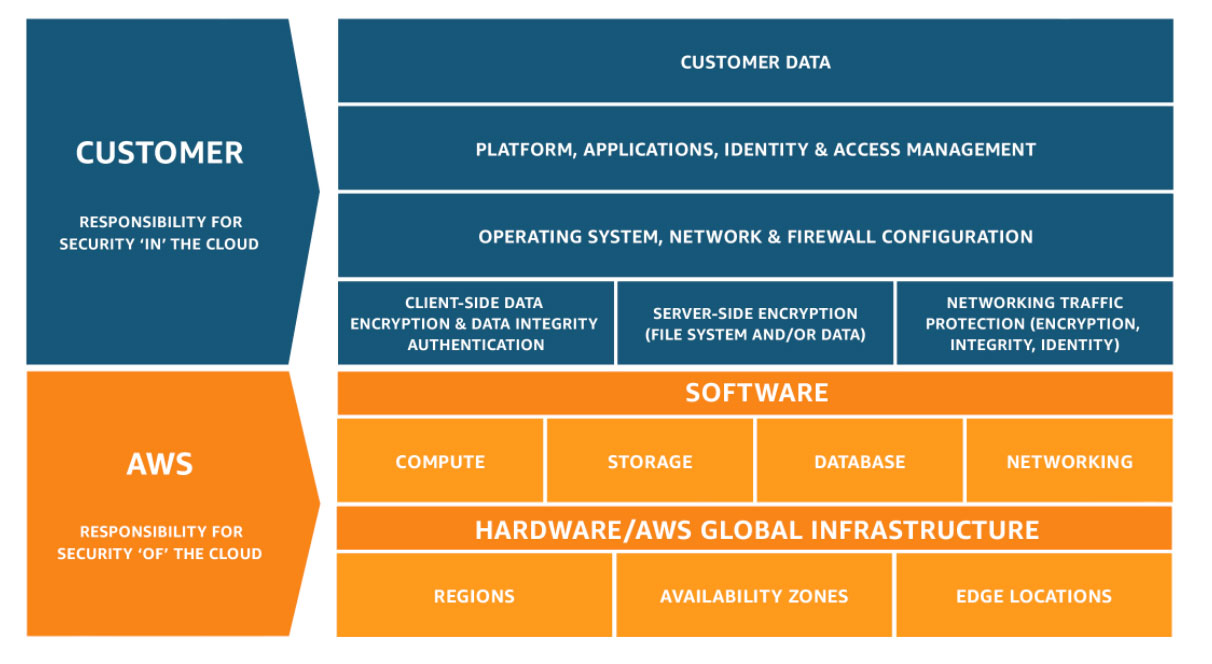
In practice, this means that an S3 customer can rely on Amazon to protect the infrastructure that S3 runs on. This infrastructure is composed of the hardware, software, networking, and facilities that run S3.
It also means that the S3 customer is responsible for managing their own data (including encryption options), classifying their assets, and using IAM (Identity and Access Management) to apply the appropriate permissions.
Fortunately, AWS provides a robust set of options for securing your data, the bulk of which I’ll take you through here.
Practical advice from AWS experts to help you weather the storm
With extensive insights, advice, and best practices from cloud leaders, our brand new white paper is the ultimate guide to optimizing your business with AWS.
Bucket Access
First, before we go any further, let me just define a few of the terms I’ll be using. When securing an S3 bucket, we can use bucket policies, ACLs (Access Control List), or IAM policies.
Bucket Policies
A bucket policy is a resource-based AWS IAM policy. You assign a bucket policy to a bucket for granting other AWS accounts, or IAM users access permissions for the bucket and the objects in it. Object permissions apply only to the objects that the bucket owner creates.
ACL (Access Control List)
Amazon S3 ACLs are another way of controlling the access to a bucket and its objects. Each bucket and object have an ACL attached to it as a subresource.
It defines the AWS accounts or groups that are granted access and what type of access they have. When a request is received against a resource, S3 checks the corresponding ACL to verify the requester has the necessary access permissions.
IAM Policies
An IAM Policy is an entity that, when attached to an identity or resource, defines their permissions. Customer-managed policies are standalone policies that are administered in your own AWS account.
AWS-managed policies are created and managed by AWS (usable but not customizable). Inline policies are those that are created and embedded directly into an IAM group, user, or role (these can’t be reused outside of where they exist).
All three types of policy can be attached to an identity (user, group, or role) in IAM to create an identity-based policy. As a best practice, try to avoid inline policies.
Configuring S3 Bucket Access
When you create a bucket, the default bucket policy is private. The same is applied to any objects that are subsequently uploaded to the bucket.
By using a combination of bucket policies, ACLs, and IAM policies, you can grant the appropriate access to the correct objects. However, this can become complex as you need to understand how all of these permissions interact.
Instead, I’d recommend that you keep it simple by separating the objects into a public bucket and a private bucket. Create a single public bucket with a bucket policy to grant access to all of the objects stored in it.
{
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::MYPUBLICBUCKETNAME/*"
}
Then create a second bucket to store all of your private objects. As this will be set to private by default, all public access will be blocked. If you wish to grant access to any of these objects, you can use IAM policies to give access to specific users or applications.
Encryption at Rest
To protect your data, you have the option of using server-side or client-side encryption.
Server-side encryption, when enabled, is managed by Amazon automatically—it will encrypt your objects before saving them on disk in its data centers and then decrypt them when you download the objects.
The encryption is achieved using default AWS-managed S3 keys or your own keys created in the Key Management Service. You must select which you want to use when enabling server-side encryption for your bucket.
Client-side encryption is when you encrypt your own data before uploading it to S3—meaning you are responsible for managing the encryption process.
As with server-side encryption, client-side encryption can help reduce risk by encrypting the data with a key that is not stored in S3.
Encryption in Transit
You can also enforce encryption during transit by requiring HTTPS to be used for all bucket operations. This can be done by adding the below code to your bucket policy.
{
"Action": "s3:*",
"Effect": "Deny",
"Principal": "*",
"Resource": "arn:aws:s3:::MYBUCKETNAME/*",
"Condition": {
"Bool": { "aws:SecureTransport": false }
}
}
Logging with CloudTrail
CloudTrail is an AWS service that maintains an audit log of all events occurring within your AWS account. The events come in two forms; management events and data events.
Management events provide information about management operations that are performed on resources in your AWS account—configuring security, for example.
Data events provide information about the operations performed on or in a resource, and these are often high-volume activities.
The management events for S3 would be things like the creation, update, or deletion of an S3 bucket, whereas the data events would be GetObject, PutObject, or DeleteObject. Data events are charged at $0.10/100,000 events.
Both management and data events are ultimately written to an S3 bucket. If you have multiple accounts, it’s possible to deliver the logs to a bucket in a management account.
Recommended best practice is to have a high-level management account, with environments being sub-accounts.
This allows you to have several control policies restricting sub-accounts from disabling CloudTrail logs, as this is the first thing a malicious attacker would want to do.
CloudWatch
Amazon CloudWatch monitors your AWS resources and applications in real-time by immediately logging events; much faster than CloudTrail’s delayed delivery of log files to S3.
Having CloudTrail setup to log S3 events to a logging bucket can often be enough, but by combining it with CloudWatch you get much more control over things like alerting and self-healing.
You can do this by setting up CloudTrail to create log streams within a CloudWatch log group. CloudTrail can then log events to this group.
By having CloudTrail events inside of CloudWatch, you’re able to achieve new things such as setting up metric filters to alert you based on suspicious activity or to run a Lambda on the triggering of an alarm to help customize your response actions.
Though this has now been made simpler by AWS Block Public Access, users would previously run a Lambda function to make a bucket private again if a PutBucketPolicy event that made it public was detected.
Lifecycle Policies
Lifecycle policies allow you to control the lifecycle of data you store in an S3 bucket. An S3 bucket can be configured so that once the data it contains is no longer required, it’s moved from standard storage into AWS Glacier.
This can both save you money by reducing storage costs and secure your data, as hackers can no longer access it. The data stored in AWS Glacier can then be retrospectively deleted if it no longer adds value to you or your organization.
S3 Block Public Access
By default, when you create a bucket, public access is blocked. However, users can modify bucket policies, access point policies, or object permissions to allow public access.
This is all fine until an overzealous developer accidentally makes your bucket public. To try and avoid mistakes like this, AWS has endeavored to become more proactive in its S3 security by introducing a new setting called Block Public Access.
Previously, as discussed above, this functionality required a combination of AWS Lambda, CloudWatch, and CloudTrail to work. This setting can be set at both the bucket level and the account level.
AWS Trusted Advisor
Trusted Advisor is an online tool that analyzes your AWS resources to help you provision them using AWS best practices.
The recommendations it gives are based on five categories, with security being one of them. Specific to S3, Trusted Advisor checks your bucket permissions to see if everything is as it should be and makes recommendations accordingly.
AWS CloudFormation Drift Detection
CloudFormation is a great way to model and provision your AWS resources, and useful for getting your application back up and running as quickly as possible during any disaster.
However, there’s always the problem of drift to consider. Drift occurs when somebody with access to your AWS management console manually changes the settings of one of your AWS resources, say while they are developing, and they forget to change it back.
With S3, this could cause security issues such as a bucket being left public or permissions being incorrect.
This is where CloudFormation Drift Detection comes in. It can be used to detect whether any of your resources have been modified from what is defined in your template.
From here, you can either manually restore the resource back to its correct state or re-run the CloudFormation stack.

Einblicke in den AWS-Markt
AWS-Jobs nach Ort
- AWS Jobs in Australien
- AWS Jobs in Österreich
- AWS Jobs in Belgien
- AWS Jobs in Bulgarien
- AWS Jobs in Tschechien
- AWS Jobs in Dänemark
- AWS Jobs in Finnland
- AWS Jobs in Deutschland
- AWS Jobs in der Schweiz
- AWS Jobs in Ungarn
- AWS Jobs in Irland
- AWS Jobs in Italien
- AWS Jobs in Luxemburg
- AWS Jobs in den Niederlanden
- AWS Jobs in Norwegen
- AWS Jobs in Polen
- AWS Jobs in Rumänien
- AWS Jobs in der Slowakei
- AWS Jobs in Südafrika
- AWS Jobs in Schweden
- AWS Jobs in der UK
- AWS Jobs in den USA